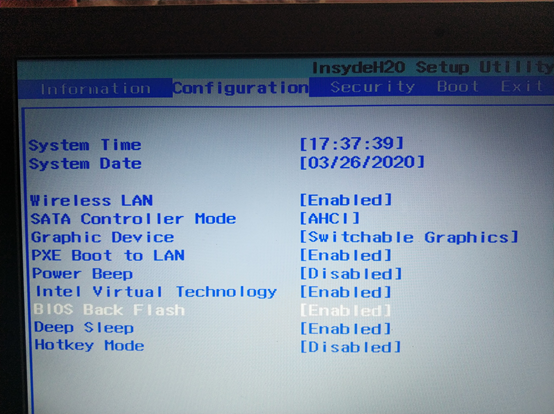
本文参考自 如何写出正确的二分查找?—— 利用循环不变式理解二分查找及其变体的正确性以及构造方式 一文,改进了原文的描述,修改了部分代码。
序言
本文以经典的二分查找为例,介绍如何使用 循环不变式 来理解算法,并利用循环不变式在原始算法的基础上根据需要产生算法的变体。谨以本文献给在理解算法思路时没有头绪而又不甘心于死记硬背的人。
二分查找究竟有多重要?《编程之美》第 2.16 节的最长递增子序列算法,如果想实现 $O (n^2)$ 到 $O (n \log n)$ 的时间复杂度下降,必须借助于二分算法的变形。其实很多算法都是这样,如果出现了在有序序列中元素的查找,使用二分查找总能比线性查找算法拥有更好的性能。
然而,虽然很多人觉得二分查找简单,但随手写一写却不能得到正确的结果:死循环、边界条件等等问题伴随着出现。《编程珠玑》第四章提到:提供充足的时间,仅有约 10% 的专业程序员能够完成一个正确的二分查找。当然,正确的二分查找和变体在算法书籍以及网络上随处可得,但是如果不加以理解,如何掌握?理解时,又往往因想不清楚,一知半解,效果有限。我在看相关的变体算法时就觉得一片茫然,不得要领:或许这个算法可以这么写,稍微变下要求就不能这么写了;举正例说明算法在某些情况下可以正常工作、举反例说明算法有错固然可行,但仅有例子是不够的,怎样一劳永逸地证明自己几经修改的算法之正确?如果每一个变体都进行孤立地理解,那么太花费时间,而且效果也不好。如何解决这个问题?在思考方法和查阅书籍之后发现,还是要靠循环不变式来完成算法正确性的理论支撑。
或许你曾了解过循环不变式,但如果不使用的话,是看不到它的强大之处的:不仅仅能帮助你证明算法正确性,同时也帮助你理解算法,甚至能帮助你在基本算法的基础上,构造出符合要求的相应算法变体。这些都将在后文的各个算法说明中看到。